資格を目指す計画的な勉強と習得した知識を活用する事例を紹介する
(某SI会社のSE論文応募で優秀論文に選ばれた作品です。)
甘 大文
2008年12月6日
日本滞在中の10年に渡って仕事に関わる資格を目指す計画的な勉強と習得した知識と技術を活用する事例を紹介し、知識を習得するノウハウと知識を活用するノウハウを社内に共有するとともに、会社に資格取得の奨励制度を提案します。資格を目指す計画的な勉強では、SEとして常に仕事に関わる知識や技術を習得する重要性を強調しながら、著者の計画的な勉強を紹介します。取得済みの資格や目標となっていた資格を説明するとともに、若者のSEに推奨したい資格を紹介します。習得した知識と技術の活用とは、元々資格を取得するきっかけは仕事ですが、習得した知識と技術はまた仕事の場面で役に立つことです。活用する事例をすべて紹介するのは無理で、知識や技術を習得する重要性を強調するために、以下の代表的な事例を紹介します。
事例1.二分探索を考案する開発(情報処理試験)
事例2.ADOのオフライン機能を導入するSNMPツールの設計開発(MCSD試験)
事例3.SQL Serverのインデックス特徴を利用する性能改善(MCDBA試験)
事例4.ROWIDを利用するデータ移行(Oracle試験)
キーワード:資格、情報処理、MCSD、MCDBA、OCP、SJC-WC、二分探索、ADO、クライアントカーソル、クラスタ化インデックス、ROWID
1.3.2. 資格取得の支援または資格保有の奨励に関する制度の提案
2.2. ADOオフライン機能を導入するSNMPツールの設計開発(MCSD試験)
2.2.1. ADOオフライン機能(非接続型データアクセス)の論理知識
2.2.2. SNMPデータ収集ツールの開発要件とレスポンスの問題点
2.3. SQLServerのインデックス特徴を利用する性能改善(MCDBA試験)
2.3.1. インデックス構成においてSQLServerとOracleの相違点
2.3.2. クラスタ化インデックス(SQLServer)の設計が問題視された事例
2.3.3. クラスタ化インデックス(SQLServer)の変更提案および性能効果
2.4. ROWIDを利用するデータ移行(Oracle試験)
2.4.1. OracleのROWIDを利用するデータ移行の背景
2.4.2. Oracleのデータ移行手順とデータIDの振り直し
本文
どの業界でもスキルの高い技術者の共通点は広く深い知識と技術をベースとする豊富な経験だと思いますが、表1に示すように他業界の技術職と比べてSI業界の技術職であるSEは新しい知識と技術を習得することがよりいっそう大切だと思われます。
| 他業界の技術職 例えば:建築士、電気士など |
SI業界の技術職(SE) | |
| 経験 | 社会人になった時点では殆ど経験がありません。仕事をしないと、経験が殆ど積めません。 | 社会人になった時点では経験がない人が多いですが、PGやOS、DBなどの経験は自宅でも積めます。 |
| 知識 | 業界知識の更新は激しくなく、さらに社会人になった時点の大卒や院卒者は既に十分な専門知識を持っています。 | 業界知識の更新は激しいです。さらに人材不足などの要因で社会人になっても最低限必要なSI知識を持っていないSEが少なくありません。 |
| 技術 | 知識と同様に技術の更新は激しくないため、経験すれば経験するほど、スキルになります。 | 知識と同様に技術の更新は激しいです。経験だけではなく、常に新しい知識と技術を習得しなければ時代に取り残されます。 |
知識と技術を習得する道筋は仕事での経験と自主的な勉強に分かれます。表2に示すように、スキルになるのはどの業界でも仕事での経験が不可欠ですが、知識と技術の系統性や将来性を図るため、自主的な勉強はとても大切だと思われます。
| 仕事での経験 | 自主的な勉強 | |
| 即戦力 | 仕事で習得する知識と技術は即戦力になります。 | 自主的な勉強で習得する知識と技術は即戦力になるとは限りません。 |
| 系統性 | 仕事で習得する知識と技術は体で覚えたものです。論理的にきちんと片付けられたものとは限らないため、系統性が足りない場合が多いです。 | 自主的な勉強で習得する知識と技術は頭で覚えたものです。通常は論理的に片付けられたものであるため、系統的な知識と技術です。 |
| 将来性 | 自主的な勉強を加えなければ、環境の変化に対応し難いです。将来が見えません。 | 直面の仕事や将来の仕事を考慮する勉強であれば、環境の変化に対応しやすいです。将来性があります。 |
自主的な勉強は受験のための勉強と受験のない勉強に分かれます。表3に示すように、受験のない勉強と比べて受験のための勉強は効果的だと思われます。
| 受験のない勉強 | 受験のための勉強 | |
| 責任感 | 目標を管理し難いため、責任が感じにくいです。 | 責任感があります。特に上司や家族など目標を管理して頂く場合。 |
| 計画性 | スケジュールを作り難いため、計画性が足りない傾向があります。 | スケジュールを作りやすいため、計画的に進めやすいです。 |
| 諦める | 諦めやすく、難しい問題を乗り越え難いです。 | 諦めにくく、難しい問題を努力して乗り越えやすいです。 |
受験のための勉強には、資格の取得や社外研修コースへの参加などがありますが、表 3に示すように、やはり社会人として資格の取得は有効な勉強方法だと思われます。
| 社外研修コース・学位学歴の取得 | 資格の取得 | |
| 生計面 | 会社の都合は個人で左右できません。因みに個人都合であれば給料を貰いません。 | 仕事の合間や私用時間を利用して勉強できる。仕事を休む必要はないため、給料が貰えます。 |
| 費用面 | 相対的に費用が高いです。 | 相対的に費用が安いです。 |
| 進捗面 | 個人都合に合わせるのは難しいです。 | 個人都合に合わせられます。 |
資格の取得は有効な勉強方法ですが、資格の設定できない勉強もあります。表5に示すのは日本滞在中の10年の勉強履歴の概要情報です。
| 資格なしの自主勉強 | 資格ありの自主勉強 | 仕事経験の勉強 | |
| 内容 | Windows、Office、パソコンの各種フリーツールや市販ツール | 情報処理:FE、SW、DB オラクル・マスタ(9i、10g) MCSD(VB6.0その他) MCDBA(SQL Server 2000その他) SJC-WC(Java言語とWeb構築) |
各種業務知識、VB、VBA、C、VC、C#、Struts、Oracle、SQL Server、HP-UNIX、PostGreSQLなど |
| 方法 | 個人購入の書籍やソフトを利用します。 | 職場の資源、個人購入の書籍やソフトを利用します。 | 職場の資源を利用します。 |
| 目標 | ケースバイケース | 公的な資格 | 仕事の遂行 |
資格を目指す受験は十分な勉強をしても合格できるとは限りません。表6に示すように、私は合計36回の受験で17回も失敗しました。また、資格を目指す受験は自己投資が必要であるため、表7に示すような相当な費用が掛かりました。
| 資格分野/受験回数 | 受験回数 | 合格回数 | 失敗回数 |
| 情報処理試験:2種 | 1 | 1 | 0 |
| 情報処理試験:基本 | 1 | 1 | 0 |
| 情報処理試験:1種 | 2 | 0 | 2 |
| 情報処理試験:DB | 4 | 0 | 4 |
| マイクロソフト認定試験 | 15 | 6 | 9 |
| オラクル・マスタ試験 | 7 | 7 | 0 |
| Sun 認定Java試験 | 3 | 2 | 1 |
| 日本語能力試験:1級 | 3 | 2 | 1 |
| 合計 | 36 | 19 | 17 |
| 分類 | 費用概算(単位:万円) |
| 書籍代(教科書、問題集) | 24 |
| ソフト(殆どiStudyの勉強用ソフト) | 21 |
| 受験チケット代(主に各ベンダー試験) | 48 |
| ネットワーク構築(主に3台PCの購入費用) | 30 |
| 合計 | 123 |
表8に示すのは日本滞在中の10年の間の主な受験履歴情報ですが、何回も失敗しても諦めず再受験することがある一方、資格取得後長い歳月を経たため再受験することもあります。例えばMCPであるソリューション アーキテクチャの合格(03/02/08)は5回目の受験で、資格取得後再受験したのは3年ぶりの基本情報処理技術者(02/10/20)の受験と4年ぶりの日本語能力1級試験の受験(06/12/03)でした。
| 日付 | 試験項目名称 | 合否 | コメント |
| 96/12/01 | 日本語能力(1級)試験 | 失敗 | 勉強不足 |
| 99/10/17 | 第2種情報処理技術者試験 | 合格 | 専門日本語の資格と認識 |
| 00/04/16 | 第1種情報処理技術者試験 | 失敗 | 勉強は十分。記述に日本語が壁 |
| 01/04/15 | 情報処理試験データベース試験 | 失敗 | 勉強は十分。論述に日本語が壁 |
| 02/06/28 | MCP(Visual Basic6.0 分散AP)試験 | 合格 | MCP(開発ツール)取得 |
| 02/08/05 | Oracle9iの4番目項目試験 | 合格 | ゴールド取得 |
| 02/09/02 | MCP(SQL Server 2000開発) | 合格 | MCP(DB)取得 |
| 02/10/20 | 基本情報処理技術者試験 ※旧第2種情報処理技術者試験 |
合格 | 3年ぶりの再受験(上位試験勉強のお陰で午前も午後も90%以上正解) |
| 02/11/25 | MCP(SQL Server 2000管理) | 合格 | 難易度が高い |
| 02/12/01 | 日本語能力1級試験 | 合格 | 6年ぶりの再受験 |
| 03/02/08 | MCP(ソリューション アーキテクチャ) | 合格 | 難易度が高い |
| 03/02/26 | MCP(Windows 2000 Serverの構築) | 合格 | 4敗で5回目合格 |
| 03/03/31 | Oracle9iの6番目項目試験 | 合格 | プラチナ取得 |
| 05/04/10 | 情報処理試験データベース試験 | 失敗 | 論文試験の語力や体力は限界。 |
| 05/06/25 | Sun認定プログラマー(SJC-P) | 合格 | Java言語を対象 |
| 06/04/02 | Sun認定Webディベロッパ(SJC-WC) | 合格 | JavaベースのWEB |
| 06/06/23 | Oracle Gold DBA10g 新機能 | 合格 | ゴールド(10g)取得 |
| 06/12/03 | 日本語能力1級試験 | 合格 | 4年ぶりの再受験 |
表9に示すのは仕事に最も役に立つ受験勉強です。表9では、試験に合格できても必ず役に立つとは限らない反面、試験に合格できなくても受験勉強が非常に役に立ったことを説明しています。例えば、情報処理試験のデータベースを今まで4回受験しても合格していませんが、受験勉強が仕事に非常に役に立っていると思います。
| 資格名称 | 合否 | 理由 |
| 基本情報処理技術者 ※旧第2種情報処理技術者試験 |
合格 | 基本レベルの受験ですが、関わる知識と技術はとても広いため、外国人である著者にとっては専門的な日本語の勉強と受験になりました。この受験勉強がなければ、その後のオラクルやマイクロソフトなどの勉強を順調に進められなかったと思います。 ※今回は習得された知識を活用する事例として二分探索の活用を紹介します。 |
| 情報処理試験:データベース | 失敗 | 年1回の受験ですが、今まで4回も惨敗しました。論文試験の日本語能力や精神的な体力が限界となり、諦めたくなくても諦めなければならない状態でした。しかしながら、この受験勉強は仕事に非常に役に立っています。この受験勉強がなければ、OracleやSQL Serverなどデータベースに関する知識や技術を簡単に習得できなかったと思いますし、その後の色々なプロジェクトの業務仕様(例えば参画経験のある某百貨店システム)を簡単に理解できなかったと思います。 |
| マイクロソフト認定:MCDBA | 合格 | 代表的なDBMSの1つであるSQL Serverの上位資格ですが、資格を取得するきっかけは元々SQL Serverの仕事であったため、勉強開始時点ですぐ実務に効果が現れました。勿論、その後の仕事でも活用する場面がとても多かったと思います。 ※今回は習得された知識を活用する事例としてSQL Serverのインデックス特徴を利用する性能改善を紹介します。 |
| マイクロソフト認定:MCSD | 合格 | 代表的な統合開発環境の1つであるMicrosoft Visual Studioの上位資格ですが、試験項目の開発言語はVB6でした。MCDBAの取得と同様に資格を取得するきっかけは元々VB6の仕事であったため、勉強開始時点でもすぐ実務に効果が現れました。 ※今回は習得された知識を活用する事例としてADOのオフライン機能を導入するSNMP収集ツールの設計開発を紹介します。 |
| オラクル認定:OCP | 合格 | 代表的なDBMSの1つであるOracleの上位資格ですが、MCDBAの取得と同様にきっかけはOracleの仕事であったため、勉強開始時点でもすぐ実務に効果が現れました。その後の仕事でも活用する場面がとても多かったと思います。 ※今回は習得された知識を活用する事例としてOracleのインデックス特徴を利用するデータ移行を紹介します。 |
| SUNのJava認定資格:SJC-WC | 合格 | 最も人気のある開発言語であるJavaの上位資格の1つです。資格を取得するきっかけは某百貨店システムの詳細設計の仕事でしたが、プログラムの経験がありませんでした。試験範囲はSUNの製品に限定されるため、役に立たないとは言えなくても、MCSDのように勉強開始時点ですぐ実務に効果が現れませんでした。 但し、この勉強履歴は今現在従事している某百貨店システムのAP保守の仕事に大変役に立っています。論文としての情報は整理されていないため、今回の事例紹介を見送りします。 |
情報処理試験とベンダー試験の相違点は表10に示し、データベース管理資格であるオラクル・マスタ(OCP)とMCDBAの相違点を表 11に示し、ソリューションデベロッパー資格であるSJC-WCとMCSDの相違点を表12に示します。
| 情報処理試験 | ベンダー試験 | |
| 範囲面 | 対象は業界共通の知識と技術で、ベンダー製品に限定されないし、且つ論理レベルの試験であるため、範囲が広いです。 | 対象はベンダー特有の知識や技術で、普通はベンダー製品に限定されるし、実務レベルの試験であるため、範囲が広くありません。 |
| 言語面 | 日本語しか出来ない試験なので、外国人技術者にとっては専門日本語の資格とも言えます。※上位資格の記述や論述試験は日本語手書きのスピードが必要と思われます。 | 普通は英語など日本語以外の言語でも受験できるため、日本語以外の言語で合格する場合、専門日本語の資格とは言えません。 |
| 体力面 | 1日最大5.5時間、連続最大2.5時間の試験であるため、高い精神的体力が必要だと思われます。 | 高い精神的体力は特に必要ないと思われます。 |
| 活用面 | 殆ど論理レベルの知識なので、実務経験がなければ上位資格を取得してもすぐに役に立つとは思われません。 | 普通は実務レベルの知識と技術なので、実務経験や実機訓練がなければ取得するのは難しいです。資格を取得すればすぐに役に立てることが多いと思われます。 |
| 優遇面 | 国家試験であるため、法的優遇があります。 例1、出入国管理および難民認定法より情報処理の資格を有しているとき、技術ビザを取得する要件である学歴や実務経験は不要です。 例2、経済産業省システムインテグレータ登録には情報処理技術者資格の保有数または保有率が重要な条件です。 |
国家試験でないため、法的優遇がありません。但し、ベンダーによってはパートナープログラム制度などにベンダーの認定資格の保有者数が条件になる場合があります。 |
| オラクル・マスタ(OCP) | MCDBA | |
| 物理設計と構築 | Oracleをベースとするデータベースの物理設計および構築に関する知識と技術が問われます。 | SQL Serverをベースとするデータベースの物理設計および構築に関する知識と技術が問われます。 |
| 論理設計と開発 | DBMSを限定しないRDBの論理設計の知識は問われません。拡張言語であるPL/SQLを用いるサーバープロシージャの開発は問われません。 | DBMSを限定しないRDBの論理設計の知識は問われるし、拡張言語であるTransact-SQLを用いるサーバープロシージャの開発は問われます。 |
| アプリケーション開発言語 | オラクル社はアプリケーションの開発言語に関する製品がないため、問われません。 | Microsoft Visual Studioの言語を用いるアプリケーションの開発は問われます。 |
| OSとNetwork | オラクル社はOSに関する製品がないため、OSに関する知識は問われません。DBに関わるネットワークの知識は少し問われます。 | Windows Serverの知識が必須で、Windowsに関する相当深く、広いOSとネットワークの知識と技術が問われます。 |
| 受験感想 | オラクルの試験は問題文が短く、かつ選択式の解答文も短いです。受験する制限時間が厳しくないし、関係知識を深く理解できなくても暗記で合格できると思われます。 | マイクロソフト(MCP)の試験は問題文が相当に長く、参考用の図と表が多いです。曖昧な解答の複数選択や遷移図を書くなど受験式があって、制限時間も厳しいです。関係知識を深く理解できなければ合格できないと思われます。 |
| SUN認定SJC-WC | マクロソフト認定MCSD | |
| 設計開発の論理知識および技術 | 設計開発の論理知識および技術は問われません。 | システム開発のポイントとして業務の概要設計と論理設計をはじめ、データベース、ネットワーク、開発言語などをトータル的に問われる必須試験として「ソリューションアーキテクチャ」項目があるため、設計開発の論理知識および技術は問われます。 |
| 開発言語 | Java | VB、VC、C#のどれか、または2つ以上の組み合わせです。 |
| WEB知識 | JavaをベースとするWEB知識と技術が問われます。 | マクロソフトの製品をベースとするWEB知識と技術が問われます。 |
| WEBサービス | WeblogicなどWEBサービスを管理するツールはSUNの製品ではないため、問われません。 | マクロソフト製品のIISが問われます。 |
| ソース管理 | よく使用するCVSはSUNの製品ではないため、問われません。 | VisualSourceSafeの知識が問われます。 |
| フレームワーク | StrutsなどフレームワークはSUNの製品ではないため、問われません。 | .NETをベースとする開発であれば、.NETのフレームワークは問われます。 |
| 開発環境 | よく使用するEclipseはSUNの製品ではないため、問われません。 | MicrosoftVisualStudioが問われます。 |
| 受験感想 | SUNの製品に限定されるため、MCSDと比べて受験範囲が狭いです。よく使用するStruts、Eclipse、WeblogicとCVSなどは対象外となるため、合格してもすぐに役に立つとは限りません。但し、後続な勉強やJavaEEの理解に有益だと思われます。 | マクロソフトはトータル的な製品を持っているため、言語だけではなく、.NETのフレームワーク、VisualSourceSafe、IISなどが問われます。暗記だけでは合格できない資格で、合格する時点ですぐに役に立てると思われます。 |
若者のSEに推奨したい資格は表13に示すように4種類に分かれますが、いずれも著者と関わっている分野なので、分野が違っているSEであれば、資格種類もまだたくさんあると思われます。
| 資格種類 | 基本レベル | 理由 |
| 上位レベル | ||
| 経済産業省認定の情報処理資格 | 基本情報処理 | 基本レベル:きちんと勉強すれば合格できなくてもかまいませんが、勉強するだけでSEに関する有益な知識や日本語の専門用語が習得できます。専門用語は業界同士のコミュニケーションの鍵であり、情報専門卒ではない日本人でも外国人でも重要だと思われます。 上位レベル:個人の都合に合わせて勿論上位レベルの資格を取れれば、スキルの上達になります。 |
| ソフトウェア開発やデータベースなど | ||
| オラクル認定のオラクル・マスタ | マスタ・ブロンズ | 基本レベル:基本レベルであるSQLの基本知識やオラクルの入門知識を習得すれば、システムの設計やプログラムの実装に役に立つと思われます。最低限の学力を持つSEはきちんと勉強すれば合格が難しくないと思われます。 上位レベル:情報処理資格と同様に上位レベルの資格を取れれば、スキルの上達になりますが、ゴールド以上の資格を取るのは高額の費用が必要であるため、推奨しません。 ※シルバー ⇒ ゴールドは約30万円、ゴールド ⇒ プラチナは約100万円が必要です。 |
| マスタ・シルバー | ||
| SUN認定のJava技術資格 | SJC-P | 基本レベル:オラクル・マスタ・ブロンズと同様にオブジェクト指向の代表的な言語としてJavaを習得すれば、システムの設計やプログラムの実装に役に立つと思われます。最低限な学力を持つSEはきちんと勉強すれば合格が難しくないと思われます。 上位レベル:個人的な都合に合わせて上位レベルの資格を取れれば、スキルの上達になります。 |
| SJC-WC | ||
| Microsoft認定の言語・DB・OS資格 | Associate (MCA) | Professional (MCP)は相当難しい試験であるため、Associate (MCA)を推奨します。但し、Visual Studio .NET、SQL Server、Windows ServerなどのMCPを取得すれば、仕事にかなり役に立つと思われます。 |
| Professional (MCP) |
前の会社で、技術職は資格に関する報告が毎年少なくとも4回ありました。これは上半期と下半期の人事評価と、4月と10月に行われる情報処理試験のタイミングに行われました。上長からの関係指示や連絡は厳しく行われましたが、個々の能力の開発や自己啓発に当たって勉強しなければならない雰囲気を強く感じていました。因みに資格取得支援または資格保有の奨励制度は我が社以外、今まで勤めた会社にはすべてありました。我が社は資格取得支援または資格保有の奨励制度がないようですので、この場で以下のように提案します。
1).資格の取得費用を補助する
資格の取得は費用が必要ですので、全額または一部を補助することを提案します。具体的な実施方法はよく検討または議論すべきですが、以下は著者の考えです。
A)一時報奨金を支払えば、別途取得費用を補助しなくてもいいです。
B)内容と達成レベルを考慮し、対象となる資格と補助する金額を決定します。
2).一時報奨金を支払う。
資格の取得は費用が必要ですので、全額または一部を補助することを提案します。具体的な実施方法はよく検討または議論すべきですが、以下は著者の考えです。
A)資格手当を毎月支払えば、一時報奨金を支払わなくてもいいです。
B)内容と達成レベルを考慮し、支払い対象となる資格と支払い金額を決定します。
3).資格手当を毎月支払う。
資格手当を毎月支払うことを提案します。具体的な実施方法はよく検討または議論すべきですが、以下は著者の考えです。
A)内容と達成レベルを考慮し、対象となる資格と支払い金額を決定します。また、支払う基準の資格レベルが高すぎないように配慮します。資格手当の支給に該当する資格レベルが高くなりますと,資格手当を貰える技術者が少なくなります。資格保有の奨励制度の効果を十分発揮するのは全社において一定割合(例えば30%)以上の技術者が資格手当を貰えるレベルまで調整するべきです。
B)支払う期間を設定します。資格は時間が経つにつれて価値が下がっていきます。再受験で資格が更新されない限り、一定期間が経つと資格手当の支給を停止するまたは支給ランクを降格するべきです。技術者達は常に新しい業務知識と先進技術を習得する必要があるため、業務知識または技術分野の資格を常に更新する必要があります。
二分探索というデータ検索アルゴリズムは大学の授業でも言及されましたが、色々な検索アルゴリズムとの比較やプログラム実例までの訓練は情報処理試験(1999年の第2種情報処理試験)を目指す勉強でした。
二分探索は整列済のデータを二つに分けて、そのどちらに検索対象が含まれているか判断するという手順を再帰的に繰り返していく検索方法です。まず、データの配列を昇順または降順に並べ、その中央の要素が検索対象と等しいかどうかを調べます。等しければそれで検索は完了し、等しくなかった場合は中央と検索対象のどちらが大きいかを比べ、配列の前半分と後半分のどちらに検索対象が含まれているかを判断します。因みに線型探索もデータ検索のアルゴリズムの一つですが、リストや配列に入ったデータに対する検索を行うにあたって、先頭から順に比較を行い、それが見つかれば終了するとう検索方法です。
データ要素数の増加に伴って、二分探索は線形探索に比べ非常に高速に探索が行えるアルゴリズムとなります。表14はデータ要素数によって探索が終了するまで比較回数(平均)を示しています。
| 要素数 | 対象が存在しない比較回数 | 対象が存在する比較回数 | ||
| 線型探索 | 二分探索 | 線型探索 | 二分探索 | |
| 2 | 2 | 2 | 1 | 1 |
| 4 | 4 | 3 | 2 | 2 |
| … | … | … | … | … |
| 16384 | 16384 | 15 | 8192 | 14 |
| 32768 | 32768 | 16 | 16384 | 15 |
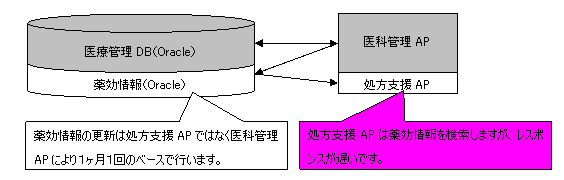
図1に示すように、某社が販売する医科管理システムパッケージには処方支援というサブシステムが付属されています。処方支援APは相互作用チェックを行うために、医科管理システムと同じ保存先のDBサーバーの薬効情報にアクセスしています。
図1 医科管理システムの処方支援システムのイメージ(更改前)
図2に示すのは更改後の医科管理システムの処方支援システムのイメージですが、本来2.1.5検索エンジンの設計開発 に置くべきで、更改前後のイメージを比較するために図 1と同じ場所に移動しました。取りあえず図 2を無視してもいいです。
図2 医科管理システムの処方支援システムのイメージ(更改後)
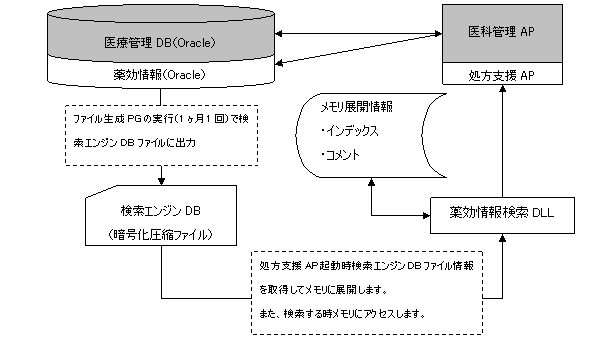
図3は処方支援APの主な処理ステップと各ステップにおいてアクセス対象となる薬効情報の主なテーブルを示しています。
図3 薬効情報の主なテーブルと処方支援APの主な処理ステップ
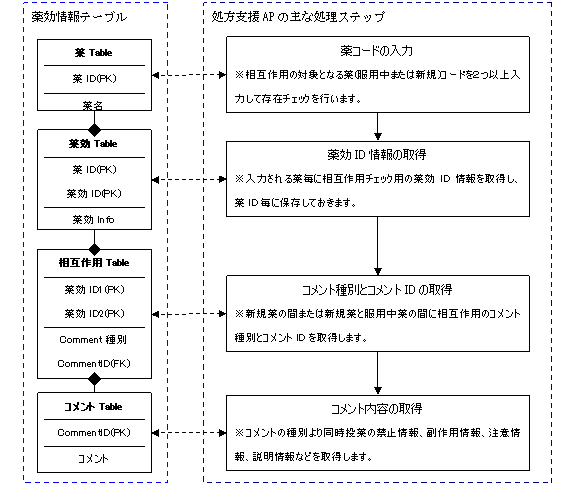
処方支援APは最悪の条件で2分以上がかかるため、1999年10月レスポンスを2秒以内に改善するユーザーの要望がありました。2分以上から2秒以内に改善する実現可能な方法を色々考案した結果、図 2に示すような検索エンジンという発想ができました。理由は以下のようであります。
①.検索対象となる薬効情報は月に1回しか更新しないため、更新に関するレスポンスを考慮する必要がありません。日常的な業務は単純な検索しか行わないため、薬効情報を複雑な管理機能を持つRDBMS(オラクル)から分離すれば、RDBMSのオーバーヘッドを削減でき、レスポンスの改善が期待できます。
②.検索対象となる薬効情報はすべてCSVファイルにダウンロードしても2MBに過ぎないため、2000年時点の普通マシンでも全情報をメモリに事前展開できます。メモリへのアクセスはハードディスクへのアクセスと比べて桁違いに速いため、メモリへの事前展開を実現すれば、レスポンスの改善がさらに期待できます。
③.検索対象となる薬効情報はオリジナルデータ情報とインデックス情報を分離し、インデックスの生成およびインデックスへの検索は二分探索を導入すれば、レスポンスの大幅改善を期待できます。
※元々は検索エンジンという言葉を使わず、薬剤相互作用チェックDLLという名前で定義しました。数年後著者はある勉強で検索エンジンという市販製品を理解した上、この薬剤相互作用チェックDLLに最も適切な名前が薬剤相互作用検索エンジンではないかと思いました。
薬剤相互作用検索エンジンの開発に導入するのは二分化探索というアルゴリズムなので、二分化探索の論理に基づき検索対象となるデータを整列するプログラム(インデックスファイルの生成)とインデックスに対する検索プログラムが不可欠となります。
薬効情報においては相互作用Tableを含む12個の類似テーブルがありますが、二分化探索という処理方法はまったく同じですので、後記は相互作用Tableを挙げて説明します。
まず、表15は相互作用Tableの主要項目の事例データですが、検索キーとなる項目(薬効ID1と薬効ID2)を整列しますと、表16に示すデータになります。また、整列の順番を示すために、IndexNoという項目(これは配列の添え字になります)を追加します。
| No | 薬効ID1 | 薬効ID2 | 種別 | 危篤度 | コメント |
| 1 | 10930 | 20069 | 2 | 3 | 副作用高:(コメント内容省略) |
| 3 | 10947 | 20052 | 1 | 4 | 投薬禁止:(コメント内容省略) |
| 5 | 10916 | 20083 | 3 | 2 | 副作用中:(コメント内容省略) |
| 6 | 10954 | 20045 | 1 | 0 | 副作用無:(コメント内容省略) |
| 7 | 10923 | 20076 | 2 | 1 | 副作用低:(コメント内容省略) |
| 8 | 10909 | 20090 | 1 | 0 | 副作用無:(コメント内容省略) |
| 10 | 10961 | 20038 | 3 | 2 | 副作用中:(コメント内容省略) |
表16に示す整列済(薬効ID1と薬効ID2の昇順)の相互作用Tableのデータに基づき、表 17に示すようにインデックス情報とコメント情報(他のテーブルであれば、インデックス情報と後続のテーブルに対する検索キー情報)を分離します。また、検索キーは複数(事例は薬効ID1と薬効ID2)があっても、桁を揃えて1つの検索キーに統合します。
| No | 薬効ID1 | 薬効ID2 | 種別 | 危篤度 | コメント | IndexNo |
| 8 | 10909 | 20090 | 1 | 0 | 副作用無:(コメント内容省略) | 0 |
| 5 | 10916 | 20083 | 3 | 2 | 副作用中:(コメント内容省略) | 1 |
| 7 | 10923 | 20076 | 2 | 1 | 副作用低:(コメント内容省略) | 2 |
| 1 | 10930 | 20069 | 2 | 3 | 副作用高:(コメント内容省略) | 3 |
| 3 | 10947 | 20052 | 1 | 4 | 投薬禁止:(コメント内容省略) | 4 |
| 6 | 10954 | 20045 | 1 | 0 | 副作用無:(コメント内容省略) | 5 |
| 10 | 10961 | 20038 | 3 | 2 | 副作用中:(コメント内容省略) | 6 |
因みに、表17に示す情報はインデックスファイル生成のプログラムに対してファイルに保存する前の情報で、検索プログラムに対してメモリに展開する情報です。
| インデックス情報 | コメント情報 | |||||
| 検索キー | IndexNo | IndexNo | 種別 | 危篤度 | コメント | |
| 1090920090 | 0 | 0 | 1 | 0 | 副作用無:(コメント内容省略) | |
| 1091620083 | 1 | 1 | 3 | 2 | 副作用中:(コメント内容省略) | |
| 1092320076 | 2 | 2 | 2 | 1 | 副作用低:(コメント内容省略) | |
| 1093020069 | 3 | 3 | 2 | 3 | 副作用高:(コメント内容省略) | |
| 1094720052 | 4 | 4 | 1 | 4 | 投薬禁止:(コメント内容省略) | |
| 1095420045 | 5 | 5 | 1 | 0 | 副作用無:(コメント内容省略) | |
| 1096120038 | 6 | 6 | 3 | 2 | 副作用中:(コメント内容省略) | |
2.1.4 検索エンジンの事例データの説明とおり、図 4に示すようにデータファイルの生成プログラムと薬剤相互作用チェックDLLを設計して開発します。データファイルは開発言語のVB6で生成し、暗号化した上で圧縮し、保存します。薬剤相互作用チェックDLLの開発言語はVC6で、ファイルのオープンはデータファイルの生成と同一ロジックで解凍した上で復号化します。
図4 検索エンジンのファイル生成機能(AP)と薬剤相互作用チェックDLL
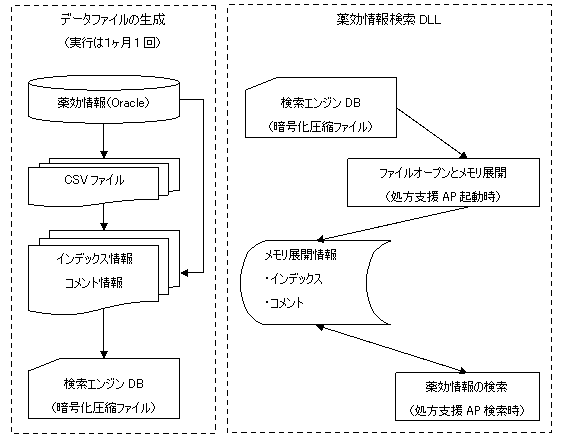
最悪要件での計測結果は0.07秒で、要望レスポンス(2秒以内)の30分の1を実現しました。薬剤相互作用チェックDLL(開発言語はVC)が当初対応できる言語はVB、DelphiとVCでしたが、1年後Java版の移植開発も依頼され、数多くの医療メーカーに販売されました。該当検索エンジンは2年後、某社の特許として認定されました。
該当仕事をする前はADOの経験もありましたが、ADOの全面的な知識の習得は2002年MCSDを目指す計画的な勉強でした。MCSDの取得ではかなり幅広い知識を勉強してきたため、多方面の仕事に役に立ちましたが、ここではその一つを例として挙げます。
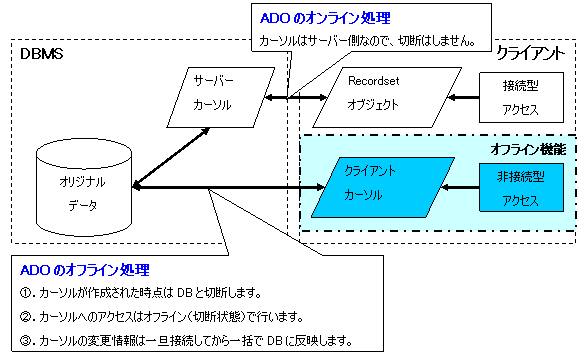
図5に示すのはごく普通のADOのオンライン(サーバーカーソル)機能とオフライン(クライアントカーソル)機能です。オフライン機能の特徴はデータベースから対象となるデータ(テーブルの全件または一部)をクライアントカーソルとして取得してからDB接続を切断します。その後はクライアントカーソルに対してデータのアクセス(検索および追加と更新)を行いますので、データベースサーバーとの通信が発生しないため、オンライン機能より速くなります。また、クライアントカーソルのデータ変更(追加または更新)がある場合、変更されたデータをオリジナルデータに反映する必要がありますが、クライアントの都合(ある変更回数に達する時やアプリケーションの終了時)でもう1回DB接続を行って変更されたデータをデータベースサーバーに送信します。オフライン機能を利用する注意点は以下です。
1).メモリ領域や通信量の制限でクライアントカーソルが大きくなってはいけません。
2).排他制御がないため、クライアントカーソルに変更されたデータは他のユーザーにより変更された場合、オリジナルデータに反映できません。
図5 ADOのオンライン(サーバーカーソル)機能とオフライン(クライアントカーソル)機能
SNMPはIP ネットワーク上のネットワーク機器を監視(モニタリング)・制御するための情報の通信方法を定めるプロトコルです。SNMP データ収集は巨大なネットワーク上で、数多くの機器の状態を把握するためには、SNMPを使い機器からの情報を集めることです。
事例であるSNMPデータ収集ツールの設計開発はデータ収集部分とデータベース保存部分に分かれます。テーブル「SNMPデータ収集」レコード情報は表18に示していますが、列「相対数」以外の情報は計算する必要がなく、既存データベースにアクセスする必要がありません。SNMPデータ収集の要件は以下です。
1).1回のSNMPデータ収集は2時間前後;
2).同一オブジェクト(IP&OID)においてデータ収集の間隔が5秒(約1440回);
3).対象となるオブジェクト(IP&OID)の数は最大5000個;
4).1回のSNMPデータ収集は約720万件。
| IP(PK) | OID(PK) | 収集時刻(PK) | 絶対数 | 相対数 | 他列数 |
| 15.15.15.15 | 1.3.6.1.5555.32.1 | 2006-08-10 01:00:00 | 4294967196 | 0.000 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.1 | 2006-08-10 01:01:00 | 4294967215 | 0.317 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.1 | 2006-08-10 01:02:00 | 4294967232 | 0.283 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.1 | 2006-08-10 01:03:00 | 4294967247 | 0.250 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.1 | 2006-08-10 01:04:00 | 4294967260 | 0.217 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.1 | 2006-08-10 01:05:00 | 4294967271 | 0.183 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.2 | 2006-08-10 01:00:00 | 4294967196 | 0.000 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.2 | 2006-08-10 01:01:00 | 4294967215 | 0.317 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.2 | 2006-08-10 01:02:00 | 4294967232 | 0.283 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.2 | 2006-08-10 01:03:00 | 4294967247 | 0.250 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.2 | 2006-08-10 01:04:00 | 4294967260 | 0.217 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.2 | 2006-08-10 01:05:00 | 4294967271 | 0.183 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.3 | 2006-08-10 01:00:00 | 4294967196 | 0.000 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.3 | 2006-08-10 01:01:00 | 4294967215 | 0.317 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.3 | 2006-08-10 01:02:00 | 4294967232 | 0.283 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.3 | 2006-08-10 01:03:00 | 4294967247 | 0.250 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.3 | 2006-08-10 01:04:00 | 4294967260 | 0.217 | ・・・ |
| 15.15.15.15 | 1.3.6.1.5555.32.3 | 2006-08-10 01:05:00 | 4294967271 | 0.183 | ・・・ |
SNMPデータ収集の要件と表18に示すテーブル「SNMPデータ収集」レコード情報を分析しますと、事前にレスポンスの問題点を想像できます。これは列「相対数」の情報を求めるのに既存データベースへとの通信が必要となり、最大720万件データの中でIPとOIDで絞ってから最も直近収集時刻の列「絶対数」と「時刻」を求める必要となります。以下は少々詳細的に説明します。
| (今回の絶対数 - 前回の絶対数) / (今回の時刻 - 前回の時刻) |
|
SELECT A.絶対数 , B.時刻 FROM SNMPデータ収集 A, ( SELECT IP, OID, MAX(時刻) AS 時刻 FROM SNMPデータ収集 WHERE IP= ? AND OID= ? GROUP BY IP, OID ) B WHERE A.IP = B.IP AND B.OID = B.OID |
前回の絶対数と前回の時刻(同一IPと同一OID)を取得するのがレコードの増加に伴って徐々に遅くなることで、列「相対数」の情報を求めるのがボトルネックになってしまうというレスポンスの問題を想像しました。
①.ADOのオフライン機能を導入する事前準備
2.2.1 ADOオフライン機能(非接続型データアクセス)で言及したオフライン機能を利用するために、まず表19に示すようにSNMPデータ収集のスナップショットデータを保存するテーブル「スナップショットデータ」を追加しました。
このテーブルは最新収集時刻のSNMPデータのみ保存するため、レコードの最大件数は5000件(テーブル「SNMPデータ収集」の最大件数の1440分の1)に過ぎません。検索の効率を考慮し、スナップショットデータというテーブルの設計に以下の工夫をしました。
・A)テーブル「SNMPデータ収集」のPKであるIPとOIDを連結して単一のPKにします;
・B)最新収集時刻のレコードのみ残すため、収集時刻からPKを外します;
・C)必須である最低限の列(絶対数と相対数)のみ残します。
| IP&OID(PK) | 収集時刻(PK) | 絶対数 | 相対数 |
| 15.15.15.15&1.3.6.1.5555.32.1 | 2006-08-10 01:05:00 | 4294967271 | 0.183 |
| 15.15.15.15&1.3.6.1.5555.32.2 | 2006-08-10 01:05:00 | 4294967271 | 0.183 |
| 15.15.15.15&1.3.6.1.5555.32.3 | 2006-08-10 01:05:00 | 4294967271 | 0.183 |
| 15.15.15.16&1.3.6.1.5555.32.1 | 2006-08-10 01:05:00 | 4294967271 | 0.217 |
| 15.15.15.16&1.3.6.1.5555.32.2 | 2006-08-10 01:05:00 | 4294967271 | 0.217 |
| 15.15.15.16&1.3.6.1.5555.32.3 | 2006-08-10 01:05:00 | 4294967271 | 0.217 |
| 15.15.15.17&1.3.6.1.5555.32.1 | 2006-08-10 01:05:00 | 4294967271 | 0.250 |
| 15.15.15.17&1.3.6.1.5555.32.2 | 2006-08-10 01:05:00 | 4294967271 | 0.250 |
| 15.15.15.17&1.3.6.1.5555.32.3 | 2006-08-10 01:05:00 | 4294967271 | 0.250 |
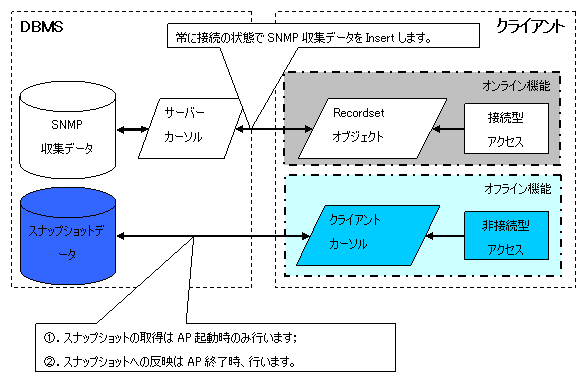
②.スナップショットデータへのアクセスはADOのオフライン機能を導入する
図 6に示すように、テーブル「SNMP収集データ」へのアクセスがADOのオンライン機能で、テーブル「スナップショットデータ」へのアクセスがオフラインで行うように設計し、直近収集時刻の絶対数と収集時刻を取得する対象をテーブル「SNMP収集データ」ではなく、テーブル「スナップショットデータ」に設計しました。
テーブル「SNMPデータ収集」へのアクセスはレコードの追加だけなので、普通のオンライン機能(サーバーかソール)を利用するのはレスポンスの問題がありません。テーブル「スナップショットデータ」へのアクセスはレコードの検索、追加と更新がありますが、検索と更新のレスポンスを改善するために、ADOのオフライン機能を利用します。既に「①. ADOのオフライン機能を導入する事前準備」で説明しましたが、テーブル「スナップショットデータ」が軽量化になっています。また、2つ以上のユーザーがデータベースに同時にアクセスすることがありませんので、ADOのオフライン機能を利用するのは問題がありません。利用する詳細仕様は以下です。
テーブル「スナップショットデータ」への初回アクセスは、全件のテーブルデータをクライアントカーソルとして取得してからDBとの接続を切断します。初回以降のテーブル「スナップショットデータ」に対するデータの取得や更新はクライアントカーソルに対して行ないますが、アプリケーションの実行が終了する時、クライアントカーソルの変更情報をデータベースサーバーに送信してオリジナルのスナップショットデータを更新します。
図6 SNMP収集データはオンライン、スナップショットデータはオフラインでアクセス
性能テスト結果、単位時間で当時性能の最もいい類似ツールの2倍の収集量を実現しました。ユーザーに非常に満足したと言われました。
データベースの資格であるMCDBAやオラクル・マスタを取得する前に、SQL ServerとOracleを数多くの案件で経験しましたが、SQL ServerとOracleに関する体系的な知識の習得はMCDBAとオラクル・マスタを目指す計画的な勉強でした。
SQL ServerでもOracleでも資格を目指す勉強で習得した知識はデータベースと関わる仕事にとても役に立ちました。この節ではインデックスの構成においてSQL ServerとOracleの相違を紹介し、後節および後章に続きその特徴を活用する事例を紹介します。
図7 SQL Serverのクラスタ化と非クラスタインデックス
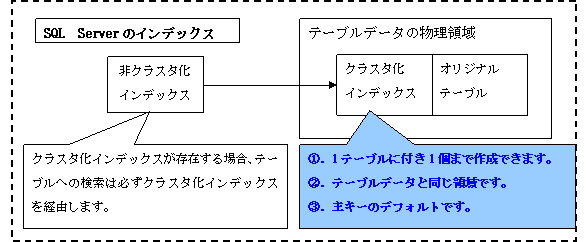
図8 Oracleの識別子(ROWID)とインデックス
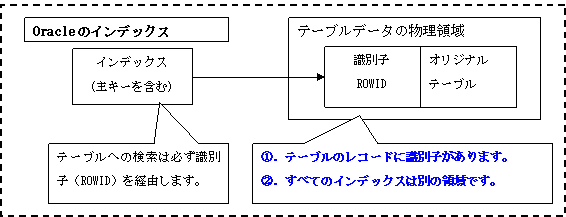
図7に示すのはSQL Serverのインデックスの構成です。クラスタ化インデックスというインデックスがありますが、オリジナルテールと同じ領域で1テーブルに付き1個しか作成できません。クラスタ化インデックスを指定する検索はオリジナルテーブルに直接なアクセスになりますが、非クラスタ化インデックスを指定する検索は必ずクラスタ化インデックスを経由します。クラスタ化インデックスはオリジナルテールと同じ領域であるため、検索用SQLの実行計画はクラスタ化インデックスが効いてもテーブルスキャンに見えます。また、主キーのインデックスはクラスタ化インデックスのデフォルトです。
図8に示すのはOracleのインデックスの構成です。OracleはSQL Serverのようなクラスタ化インデックスがありませんが、SQL Serverにない識別子(ROWID)があります。識別子(ROWID)を指定する検索はオリジナルテーブルに直接なアクセスになりますが、主キーを含むすべてのインデックスを指定する検索は必ず識別子(ROWID)を経由します。
インデックス構成においてSQL ServerとOracleの主な相違点は表20に示されます。
| SQL Server | Oracle | |
| ROWID | なし | ROWIDは擬似列で、表のどのレコードにも内部的に持っているBASE64文字列のことです。またデータ型の1つであり、ROWID型の列を定義できます。 |
| クラスタ化インデックス | クラスタ化インデックスは、データ行をそのキー値に基づいて並べ替え、テーブル内に格納します。 | なし |
| 主キーの保存場所 | クラスタ化インデックスである場合テーブルと同一領域ですが、非クラスタ化インデックスである場合テーブルと違う領域です。 | 必ずテーブルと違う領域です。 |
クラスタ化インデックスの設計が問題となる事例は某ERP案件のデータベース性能改善の仕事です。表21に示すのはインデックスの設計が問題となるテーブルおよびインデックスの項目詳細ですが、図 9に示すのは問題となるテーブルにおいて全インデックスの検索ルートです。
| 列名 | 型 | size | Not Null | クラスタ化(PK) | 非クラスタインデックス | ||||
| I1 | I2 | I3 | I4 | I5 | |||||
| C1 | varchar | 10 | ● | ● | |||||
| C2 | varchar | 10 | ● | ● | ● | ||||
| C3 | varchar | 20 | ● | ● | |||||
| C4 | varchar | 10 | ● | ● | ● | ||||
| C5 | varchar | 40 | ● | ● | ● | ||||
| C6 | varchar | 20 | ● | ● | |||||
| C7 | varchar | 30 | ● | ● | ● | ||||
| C8 | int | ● | ● | ||||||
| C9 | int | ● | ● | ● | |||||
| C10 | varchar | 10 | ● | ● | ● | ||||
| C11 | varchar | 10 | ● | ||||||
| C12 | varchar | 10 | ● | ||||||
| C13 | varchar | 10 | ● | ||||||
| C14 | varchar | 10 | |||||||
図9 問題となるテーブルにおいて全インデックスの検索ルート
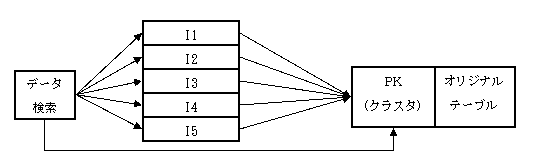
表21に示すように問題となるテーブルのクラスタ化インデックスは合計10項目があり、単純的な項目のサイズ合計が148バイトに達します。実装されているSQLを調査しますと、非クラスタ化インデックスであるI1~I5がよく使われていますが、クラスタ化インデックスが1回も使われていません。そのため、図 9に示すように問題となるのは非クラスタインデックスであるI1~I5は項目数も少なく、単純的な合計サイズも小さいですが、テーブルへのアクセスは合計10項目を持つクラスタ化インデックスを経由しなければなりません。
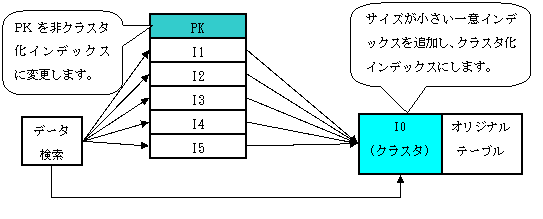
2.3.2クラスタ化インデックス(SQL Server)の設計が問題視された事例について、合計10項目を持つPKはクラスタ化インデックスになっていることが問題であるため、表22のように項目C0を追加し、図 10に示すようにPKからクラスタ化インデックスを分離すれば、問題を解決できると思われます。
図10 変更後の全インデックスの検索ルート
| 列名 | 型 | size | Not Null | クラスタ化I0 | 非クラスタインデックス | |||||
| PK | I1 | I2 | I3 | I4 | I5 | |||||
| C0 | int | (IDENTITY) | ● | ● | ||||||
| C1 | varchar | 10 | ● | ● | ||||||
| C2 | varchar | 10 | ● | ● | ● | |||||
| C3 | varchar | 20 | ● | ● | ||||||
| C4 | varchar | 10 | ● | ● | ● | |||||
| C5 | varchar | 40 | ● | ● | ● | |||||
| C6 | varchar | 20 | ● | ● | ||||||
| C7 | varchar | 30 | ● | ● | ● | |||||
| C8 | int | ● | ● | |||||||
| C9 | int | ● | ● | ● | ||||||
| C10 | varchar | 10 | ● | ● | ● | |||||
| C11 | varchar | 10 | ● | |||||||
| C12 | varchar | 10 | ● | |||||||
| C13 | varchar | 10 | ● | |||||||
| C14 | varchar | 10 | ||||||||
インデックスが多いテーブルはクラスタ化インデックスを以下の優先順位で選定します。
・A)既存の項目が少なくサイズが小さい一意インデックスをクラスタ化にします。
・B)予想で使用する頻度の高い一意インデックスをクラスタ化にします。
・C)IDENTITY列を追加してクラスタ化インデックスにします。
変更後性能測定結果は該当テーブルへのアクセスはトータル的にアクセス時間が変更前の44%になりました。テーブルおよびインデックスの保存領域の増加は約5%でした。
OracleのROWIDおよびインデックスは既に2.3.1インデックス構成においてSQL ServerとOracleの相違点で紹介しましたので、この節ではOracleのインデックスとROWIDの説明を省略します。
今までOracleデータ移行の仕事にインデックスの代わりにROWIDを利用する経験は何回かありましたが、ここではその一つを例として挙げて、インデックスを利用する場合とROWIDを利用する場合のレスポンス性能差を説明します。
表23に示すのは文書管理データを保存するテーブルの項目定義ですが、実データは表24~表26に示すように5つのテーブル(データ3とデータ5は省略)に保存され、さらにPKであるデータIDの値は5つのテーブルでも1から起算され、重複されています。5つのテーブルも一意なインデックスIndex1がありますが、Index1の項目であるタイトル(DOCTITLE)がそのテーブルに限らず、5つのテーブルにまたがって一意になっています。今回紹介する仕事は文書管理データのテーブル定義を変更せず、図 11に示すように5つのテーブルのデータを1つのテーブルに移行し、データIDの値をタイトル(DOCTITLE)の昇順で1から振り直します。
| 列名 | データ型 | サイズ | PK | Index1 | 備考 |
| DATAID | CHAR | 8 | ● | データID | |
| DB_ID | VARCHAR2 | 1 | テーブルの保存DB番号 | ||
| DOCTITLE | VARCHAR2 | 250 | ● | タイトル(全データに対する一意) | |
| DOCPATH | VARCHAR2 | 250 | フルパス | ||
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| DATAID | DB_ID | DOCTITLE | DOCPATH |
| 1 | 1 | 19981001001 | /home/NSIDX01/19981001001.html |
| 2 | 1 | 19981001006 | /home/NSIDX01/19981001006.html |
| 3 | 1 | 19981001011 | /home/NSIDX01/19981001011.html |
| 4 | 1 | 19981001016 | /home/NSIDX01/19981001016.html |
| ・・・ | ・・・ | ・・・ | ・・・ |
| 120000 | 1 | 20071010000 | /home/NSIDX01/20071010000.html |
| DATAID | DB_ID | DOCTITLE | DOCPATH |
| 1 | 2 | 19981001003 | /home/NSIDX02/19981001003.html |
| 2 | 2 | 19981001008 | /home/NSIDX02/19981001008.html |
| 3 | 2 | 19981001013 | /home/NSIDX02/19981001013.html |
| 4 | 2 | 19981001018 | /home/NSIDX02/19981001018.html |
| ・・・ | ・・・ | ・・・ | ・・・ |
| 120000 | 2 | 20071010002 | /home/NSIDX02/20071010002.html |
| DATAID | DB_ID | DOCTITLE | DOCPATH |
| 1 | 5 | 19981001005 | /home/NSIDX05/19981001005.html |
| 2 | 5 | 19981001010 | /home/NSIDX05/19981001010.html |
| 3 | 5 | 19981001015 | /home/NSIDX05/19981001015.html |
| 4 | 5 | 19981001020 | /home/NSIDX05/19981001020.html |
| ・・・ | ・・・ | ・・・ | ・・・ |
| 120000 | 5 | 20071010004 | /home/NSIDX05/20071010004.html |
図11 文書データのマージ処理図

2.4.1 OracleのROWIDを利用するデータ移行の背景に続き、図 12に示しますようにデータ移行の手順とデータIDの振り直しを説明します。
図12 データ移行の手順とデータIDの振り直し
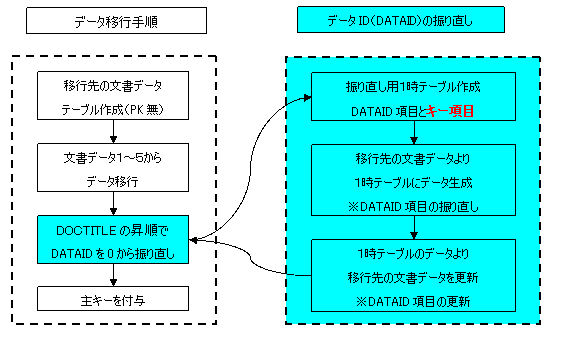
図13 データID振り直しの案1と案2の比較
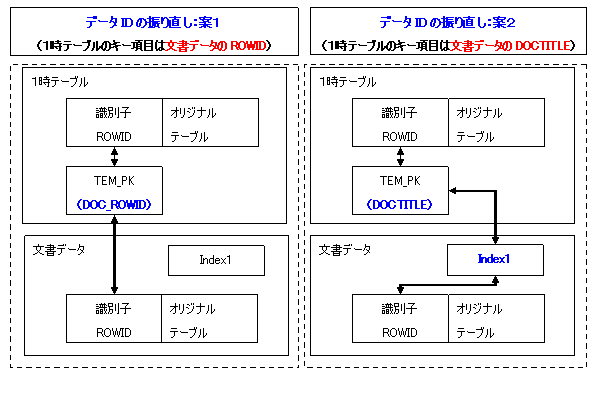
約60万件のレコードに対してデータIDの振り直しを行う場合、ROWIDもインデックスも使用しなければ、約1800億(文書データの60万件 X 1時テーブルへの平均検索回数30万回 )回の検索が必要となるため、相当な時間がかかると想定できます。確かに、データIDの振り直しはROWIDもインデックスも使用しないことを考えていなかったです。図 13に示しますように、案1のキー項目はROWID型で文書データのROWIDの値を保持し、案2のキー項目は文書データのDOCTITLEと同じデータ型で、DOCTITLEの値を保持します。案1の場合、Index1を経由せず直接文書データのROWIDを参照して振りなおされたデータIDで更新を行いますが、案2の場合、Index1を経由してから文書データのROWIDを参照して振りなおされたデータIDで更新を行います。
ROWID(案1)とインデックス(案2)を使用するSQL文は図 14に示します。
図14 データID振り直しの案1と案2のSQL比較

レスポンスの測定結果:案1は15分で、案2は185分でした。
※.上記同じデータでROWIDもインデックスも使用しない案を確認しようとしましたが、10時間でも終わらないので、諦めて強制終了しました。